RAG: Když umělá inteligence ví, kde hledat odpovědi

Pavel Seidl 23. 7. 2025

V dnešní době se umělá inteligence stala klíčovým prvkem pro inovace napříč odvětvími. Zejména velké jazykové modely (LLM), jako je GPT-4, Gemini a mnoho dalších, transformují způsob, jakým pracujeme s informacemi a píšeme texty. Nicméně, i ty nejsofistikovanější LLM mají svá omezení – mohou generovat halucinace, tedy informace, které nejsou fakticky správné, a často postrádají aktuální znalosti o světě za hranicí jejich trénovacích dat. Zde přichází na scénu technologie Retrieval-Augmented Generation (RAG), která tyto nedostatky řeší.
Co je to RAG a proč je důležitý?
RAG je technika, která kombinuje sílu LLM s vyhledávacími systémy. Jednoduše řečeno, předtím než LLM vygeneruje odpověď, RAG systém vyhledá relevantní informace z externí databáze (například z dokumentů vaší firmy, webových stránek, nebo vědeckých článků). Tyto nalezené informace jsou pak poskytnuty LLM jako dodatečný kontext, což mu umožňuje generovat přesnější, relevantnější a aktuálnější odpovědi, minimalizovat halucinace a odkazovat se na konkrétní zdroje.
Představte si to jako inteligentního asistenta, který si před odpovědí nejprve prohledá firemní knihovnu, a pak teprve na základě nalezených informací formuluje odpověď.
Například když si do RAGu přidáme předpisy o letovém provozu, tak může dotazování a odpověď vypadat následovně:
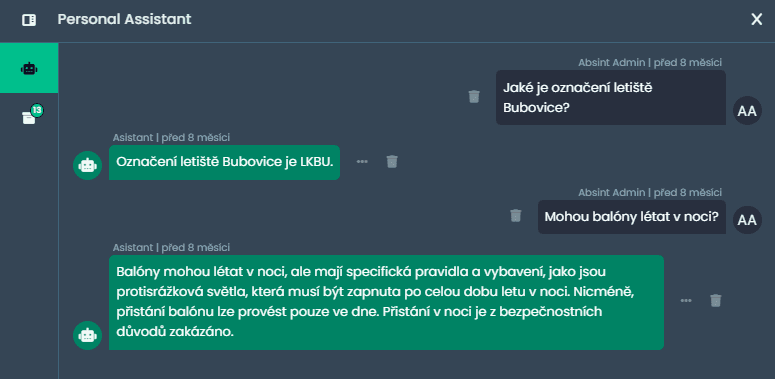
Navíc je možné si zkontrolovat, odkud si vzal asistent informace uvedené v odpovědi:
Základní přístup k RAG: Přímočaré, ale s limity
Základní implementace RAGu, neboli naivního RAGu, je poměrně jednoduchá a představuje dobrý start pro pochopení konceptu:
- Zpracování vstupních dat: (A) všechny data na vstupu se zpracují a převedou do textu.
- Indexování dokumentů: (B) všechny dokumenty, ze kterých chceme vyhledávat, se rozdělí na menší kusy (tzv. chunks nebo pasáže).
- (C) Každý chunk je poté převeden do vektrové reprezentace (embedding) pomocí speciálního modelu. (D) Tyto vektory jsou uloženy ve vektorové databázi.
- Dotaz uživatele: (1) když uživatel položí dotaz, i tento dotaz je převeden na vektorové vložení.
- Vyhledávání: (2) vektorový dotaz se porovná s vektory v databázi a najdou se nejpodobnější (nejrelevantnější) chunks (3).
- Generování odpovědi: (4) nalezené chunks jsou spolu s původním dotazem předány LLM, který na základě nich generuje finální odpověď (5).
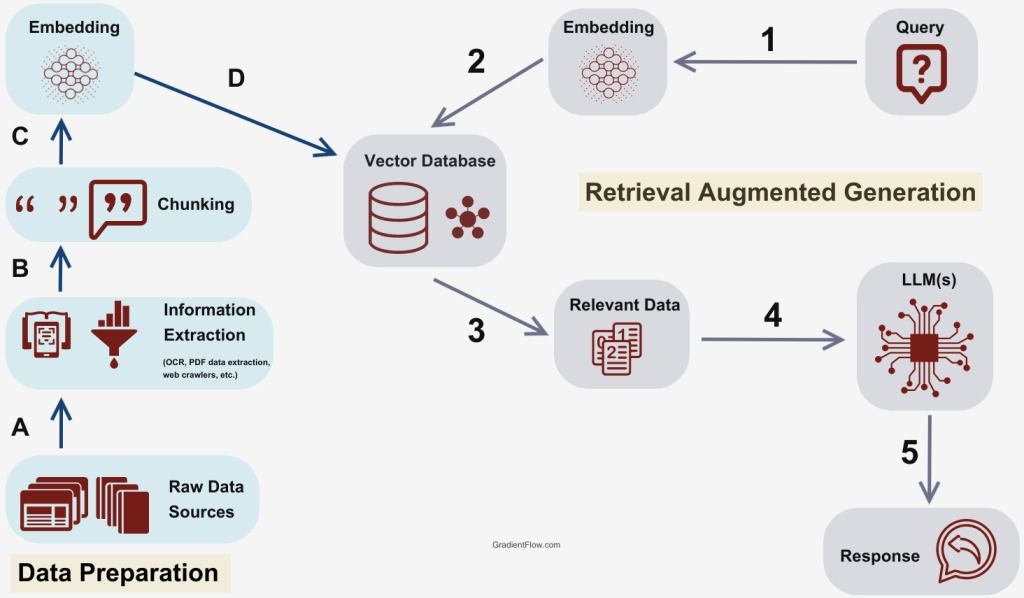
https://gradientflow.com/techniques-challenges-and-future-of-augmented-language-models/
Tento naivní přístup funguje dobře pro jednoduché případy, ale brzy narazí na své limity. Co když je dotaz složitý a vyžaduje informace z více částí dokumentu? Co když je nalezený chunk irelevantní nebo příliš krátký? Na to vše máme u nás odpovědi i řešení pomocí pokročilejších technik RAGu. Rádi vám pomůžeme inteligentně vyhledávat ve vašich datech.
DATERA a RAG: Přinášíme inteligenci do vašich dat
V Dateře vidíme obrovský potenciál metody RAG pro naše klienty. Implementací této techniky jim můžeme pomoci:
- Zlepšit zákaznickou podporu: Automatizované chatboty mohou poskytovat přesné a aktuální informace z firemních znalostních bází.
- Zefektivnit interní procesy: Zaměstnanci mohou rychleji nacházet potřebné informace v rozsáhlé dokumentaci.
- Podpořit rozhodování: Manažeři mohou získávat rychlé a fakticky podložené shrnutí z velkého množství dat.
- Inovovat v produktech: RAG může být základem pro nové inteligentní aplikace, které využívají specifická firemní data.
Máme znalosti RAGu od jeho základních principů až po komplexní implementace. Jsme připraveni vám pomoci navrhnout a implementovat robustní RAG řešení, které bude přesně odpovídat vašim potřebám a cílům.
____________________________________________________________________________________________
Chcete se dozvědět více o tom, jak může RAG pomoci vaší firmě? Kontaktujte nás a proberme vaše možnosti!
Pavel Seidl 23. 7. 2025
